
TL;DR:
- Voice synthesis has advanced to produce natural, emotionally expressive speech that is often indistinguishable from a human voice. It is widely applied in customer service, healthcare, media, and accessibility, offering benefits like scalability, personalization, and cost savings. However, ethical concerns around consent, data ownership, and misuse remain critical considerations for responsible deployment.
Voice synthesis has moved well beyond the monotone, robotic speech most people picture. Today’s technology can replicate emotion, rhythm, and natural cadence so convincingly that listeners often cannot tell the difference from a real human voice. If you work in business, tech, media, or customer service, understanding what is voice synthesis matters more now than ever before. This guide covers the fundamentals, explains how it works, explores its applications, and addresses the ethical questions every professional needs to understand before deploying it.
Table of Contents
- Key takeaways
- What is voice synthesis: the fundamentals
- How voice synthesis works
- Applications and benefits of voice synthesis
- Challenges, ethics, and what comes next
- My take on voice synthesis
- How Aimagency puts voice synthesis to work
- FAQ
Key takeaways
| Point | Details |
|---|---|
| Voice synthesis defined | It converts text into spoken audio using AI models that replicate tone, rhythm, and emotion. |
| Neural TTS is the standard | Deep learning has replaced older methods, producing far more natural-sounding output. |
| Data requirements vary | Zero-shot cloning needs just 3 to 10 seconds of audio; full fine-tuning requires hours. |
| Applications span many sectors | Customer service, healthcare, media, and accessibility all rely on voice synthesis today. |
| Ethics cannot be ignored | Consent, data ownership, and misuse of cloned voices are active industry concerns. |
What is voice synthesis: the fundamentals
Voice synthesis is the artificial production of human speech from text or other inputs. It is also referred to as text-to-speech (TTS) technology, though voice synthesis is the broader term that includes voice cloning, emotional speech generation, and even singing voice synthesis.
The core process involves several stages working together:
- Text input and analysis: The system reads written text and breaks it into linguistic units.
- Phoneme conversion: Words are converted into phonemes, the smallest units of sound in a language.
- Prosody modelling: The system determines rhythm, stress, and intonation to make speech sound natural.
- Speech generation: Audio is produced from the modelled parameters and delivered as an output file or real-time stream.
Earlier approaches used concatenative synthesis, which stitched together pre-recorded audio fragments. The results sounded choppy and unnatural. Neural TTS captures prosody, emotion, and rhythm in a way that older concatenative methods simply could not achieve. Deep learning models trained on vast speech datasets now generate voices that feel genuinely human.
Voice cloning is a related but distinct application. Rather than generating a generic voice, cloning creates a replica of a specific person’s vocal characteristics. This is where the technology becomes both powerful and ethically complex.
Pro Tip: When evaluating voice synthesis tools, listen for prosody quality first. A system that handles pauses, stress, and sentence-ending intonation well will always sound more credible than one that merely pronounces words correctly.
How voice synthesis works
Understanding the technical workflow helps you make smarter decisions when choosing or building voice synthesis solutions.
From text to audio: the processing pipeline
When text enters a TTS or voice synthesis system, it passes through a natural language processing (NLP) layer. This layer handles punctuation, abbreviations, numbers, and sentence structure. It then feeds into an acoustic model that predicts the audio features corresponding to each phoneme. Finally, a vocoder converts those predicted features into a playable audio waveform.

Modern systems go further. AI models that interpret context for expressive speech can adjust tone and emphasis dynamically, even recognising sarcasm or irony. That is a significant departure from the flat, literal speech of earlier generations.
Voice cloning model types
Different use cases require different approaches, and the amount of audio data needed varies considerably.
| Model type | Audio required | Best suited for |
|---|---|---|
| Zero-shot cloning | 3 to 10 seconds | Quick personalisation, demos |
| Few-shot cloning | 1 to 5 minutes | Brand voice, content production |
| Full fine-tuning | Several hours | High-fidelity, production-grade replicas |
Zero-shot cloning requires as little as 3 seconds of audio, making it accessible for rapid prototyping. Full fine-tuning demands significantly more data but delivers far greater accuracy and consistency.
On-device efficiency and language support
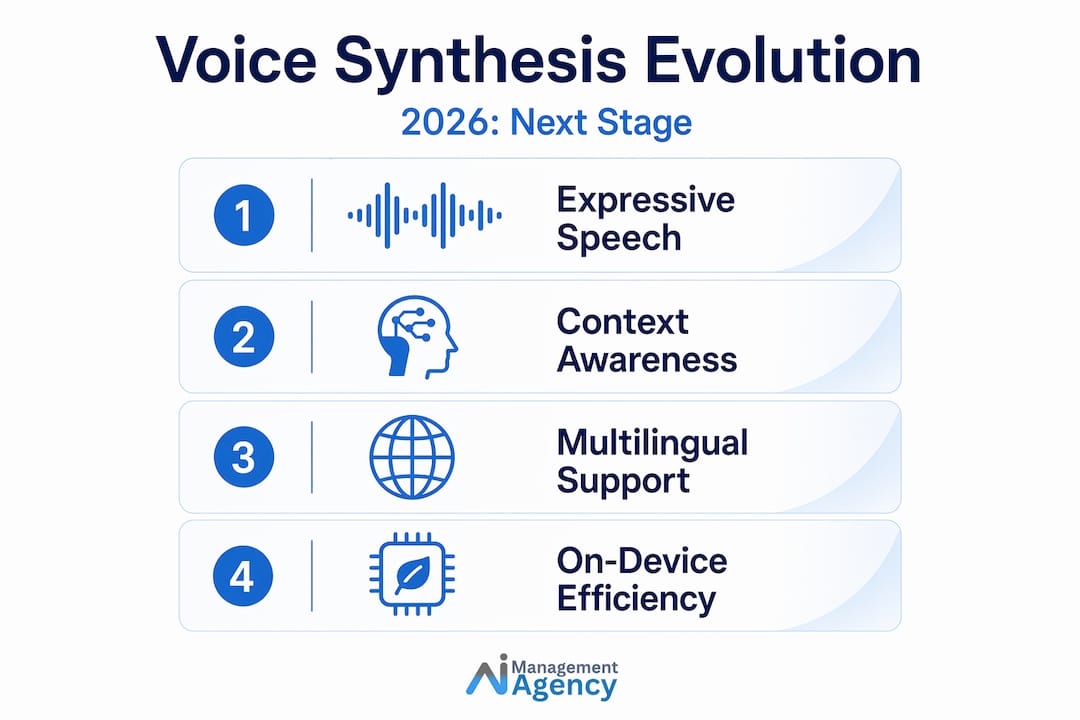
One of the most significant recent shifts is the move towards on-device voice synthesis. Modern on-device TTS models generate 10 seconds of speech in roughly 1.6 seconds while occupying as little as 404 MB and supporting over 30 languages. This makes private, low-latency voice synthesis viable even on mobile hardware. Models such as Supertone’s Supertonic 3 demonstrate on-device TTS with 31-language support and expressive tag handling, pushing the boundary of what is achievable without cloud dependency.
Pro Tip: For natural-sounding output, keep sentences under 25 words and separate dialogue with paragraph breaks. This gives the synthesis engine clear cues for natural pacing and breathing rhythm.
Applications and benefits of voice synthesis
The practical reach of voice synthesis technology is broad, and it is growing. The voice cloning market is projected to reach USD 16.2 billion by 2032, driven by adoption across media, healthcare, and customer service. That figure reflects genuine utility, not speculation.
Where voice synthesis is being used
- Customer service and AI voice agents: Businesses deploy AI voice agents to handle inbound calls, answer questions, and book appointments. These agents speak with natural tone and cadence, reducing reliance on human staff for repetitive queries.
- Healthcare: Voice synthesis assists patients with communication difficulties and powers clinical documentation tools. It also supports telemedicine by providing clear, accessible verbal instructions.
- Media and content creation: Publishers and broadcasters use TTS to produce audio versions of written content at scale. Personalised narration is now commercially viable for individual articles and reports.
- Accessibility: Screen readers powered by neural TTS make digital content far more usable for visually impaired users. The improvement in naturalness significantly reduces listening fatigue.
- Education and e-learning: Multilingual voice synthesis allows training materials to be localised quickly without re-recording by human voice actors.
- Entertainment: Singing voice synthesis and emotional speech generation are entering gaming, film, and interactive media production.
The benefits that drive adoption
The reasons organisations invest in voice synthesis go beyond novelty. The core benefits are practical and measurable:
- Scalability: One voice model can handle thousands of simultaneous interactions without additional cost per call.
- Personalisation: Fine-tuned models allow businesses to create a consistent branded voice across all customer touchpoints.
- Multilingual support: A single deployment can serve customers across dozens of languages, removing the need for multiple human recording sessions.
- Availability: AI voice agents using voice synthesis operate continuously, including outside business hours, without fatigue or inconsistency.
- Cost efficiency: Reducing dependence on human agents for routine calls lowers operational costs while maintaining service quality.
The combination of availability, consistency, and scalability is why AI voice agents in B2B sales and engagement are attracting serious investment from businesses of all sizes.
Challenges, ethics, and what comes next
Voice synthesis is powerful. That power comes with genuine responsibilities and real technical limitations.
Ethical concerns professionals must take seriously
- Consent and ownership: Cloning a person’s voice without permission is an ethical and, in many jurisdictions, a legal issue. Ethical challenges include consent and risks of misuse of synthetic voices, and industry pressure for clear frameworks is growing.
- Fraud and deception: Cloned voices have been used in financial scams and misinformation campaigns. Organisations deploying voice cloning must implement safeguards to prevent misuse.
- Data governance: Voice data used to train or fine-tune models must be stored and processed responsibly. Who owns a cloned voice is still being debated in many legal systems.
“Ethical use of voice cloning requires informed consent and robust data governance to maintain trust.” — Voice Cloning Market report
Technical challenges in production environments
Beyond ethics, technical hurdles remain. Long inputs can cause TTS engines to fail silently, and chunking text at sentence boundaries is the standard workaround in production systems. Cost is another factor. Caching audio outputs reduces recurring cloud TTS expenses significantly, particularly for frequently repeated content.
What the near future looks like
The direction of travel is clear. Voice synthesis will become more expressive, more contextually aware, and more linguistically diverse. NLP integration is already allowing models to interpret intent and adjust delivery accordingly. Broader language and dialect support will follow. For professionals, the question is not whether to engage with this technology. It is how to do so responsibly and effectively.
My take on voice synthesis
I have watched voice synthesis technology move from a curiosity to a genuine business tool over several years, and the pace of change in the last 18 months has been remarkable. What strikes me most is not the technical achievement. It is how quickly the gap between “clearly a robot” and “sounds like a person” has closed.
Where I think many organisations get this wrong is in treating voice synthesis as a cost-cutting measure first and a communication tool second. The businesses getting real value from it are the ones that invest in voice design: choosing the right tone, testing how their audience responds, and iterating. A poorly designed AI voice agent undermines trust faster than a slow website.
The ethics piece is non-negotiable. I have seen projects rushed to deployment without proper consent frameworks or data governance in place. That is a liability, not a shortcut. Any professional considering voice cloning, particularly for customer-facing applications, needs to treat consent and data ownership with the same rigour as financial compliance.
What I would watch most closely going forward is the integration of real-time NLP with voice synthesis. When a system can genuinely interpret emotional context and adjust its delivery mid-conversation, the quality of human-machine interaction changes fundamentally. We are close, but not quite there yet.
— Geoff
How Aimagency puts voice synthesis to work
At Aimagency, we build AI voice agents that go beyond basic text-to-speech. Our agents speak with natural tone, handle complex questions, and operate around the clock. We have deployed voice solutions across hospitality, finance, and professional services, each tailored to the specific communication needs of that sector.
If you are in hospitality, our voice AI for guest service handles enquiries, reservations, and FAQs without putting guests on hold. For financial services, our AI receptionist for finance manages inbound calls, qualifies prospects, and books appointments. Every agent is built on the same principle: reliable, natural-sounding communication that represents your business well. Want to understand what makes a high-performing AI voice agent different from a basic TTS solution? Read our breakdown of what makes ‘Daisy’ perform and see the architecture behind our best results.
FAQ
What is voice synthesis in simple terms?
Voice synthesis is technology that converts written text into spoken audio using artificial intelligence. Modern systems produce natural-sounding speech with appropriate tone, rhythm, and emotion, far beyond the robotic voices of earlier TTS tools.
How does voice synthesis work?
Text is processed by an NLP layer, converted into phonemes, modelled for prosody, and then rendered into audio by a vocoder. Neural TTS models trained on large speech datasets handle this pipeline end to end, producing human-like output.
What are the main applications of voice synthesis?
Voice synthesis is used in AI voice agents for customer service, healthcare communication, accessibility tools, content creation, e-learning, and entertainment. It allows businesses to deliver consistent, scalable, multilingual voice interactions.
What are the benefits of voice synthesis for businesses?
The primary benefits include 24/7 availability, scalability across thousands of simultaneous calls, consistent brand voice, multilingual support, and reduced operational costs compared to solely human-staffed communication teams.
Is voice cloning ethical?
Voice cloning raises legitimate concerns around consent and data ownership. Ethical use requires explicit permission from the person whose voice is being cloned, transparent data governance, and safeguards against misuse for fraud or deception.
Recommended
- What is voice AI for hotels? 90% fewer calls guide – AI Management Agency
- The Anatomy of a High-Performing AI Voice Agent: What Makes ‘Daisy’ Different? – AI Management Agency
- Voice AI for Hospitality – Boosting Guest Service Efficiency – AI Management Agency
- What is speech-to-text AI: a UK small business guide – AI Management Agency


